
Bytedance, the parent company of Tiktok, has introduced Omnihuman-1, an AI model that can convert a single image and audio clip into a surprisingly realistic human video. The level of realism is very accurate, making it more and more difficult to distinguish the actual video and its output.
OMNIHUMAN-1 can generate fluids and natural movements at all aspect ratio or body ratio, and ensure seamless adaptation to different formats. With just one image and audio truck, it generates a very real human video and captures with incredible accuracy of facial expressions, gestures, and voice synchronization. This technology focuses on its abilities, but is currently unable to disclose or download it.
According to the information shared on the GitHub project page, Omnihuman was designed to create human videos from a single image using motion quuens such as audio, video, or combination of both. It is an advanced AI framework. Unlike the previous model, which was struggling with data restrictions, Omnihuman uses a multi -modal training strategy to improve accuracy and realism, even if it is minimal input. This system works in an image of any aspect ratio (poretry, half body, or whole body) that introduces a very realistic result in various formats.
“We are a human video with the end -to -end multi -modality condition named Omnihuman, which can generate human videos based on a single human image and motion signal (only audio, video, audio and video combination) The researcher of the generated framework has been posted on GitHub.
Bytedance argued that Omfman, especially when producing realistic human movements from only audio alone, exceeds existing methods.
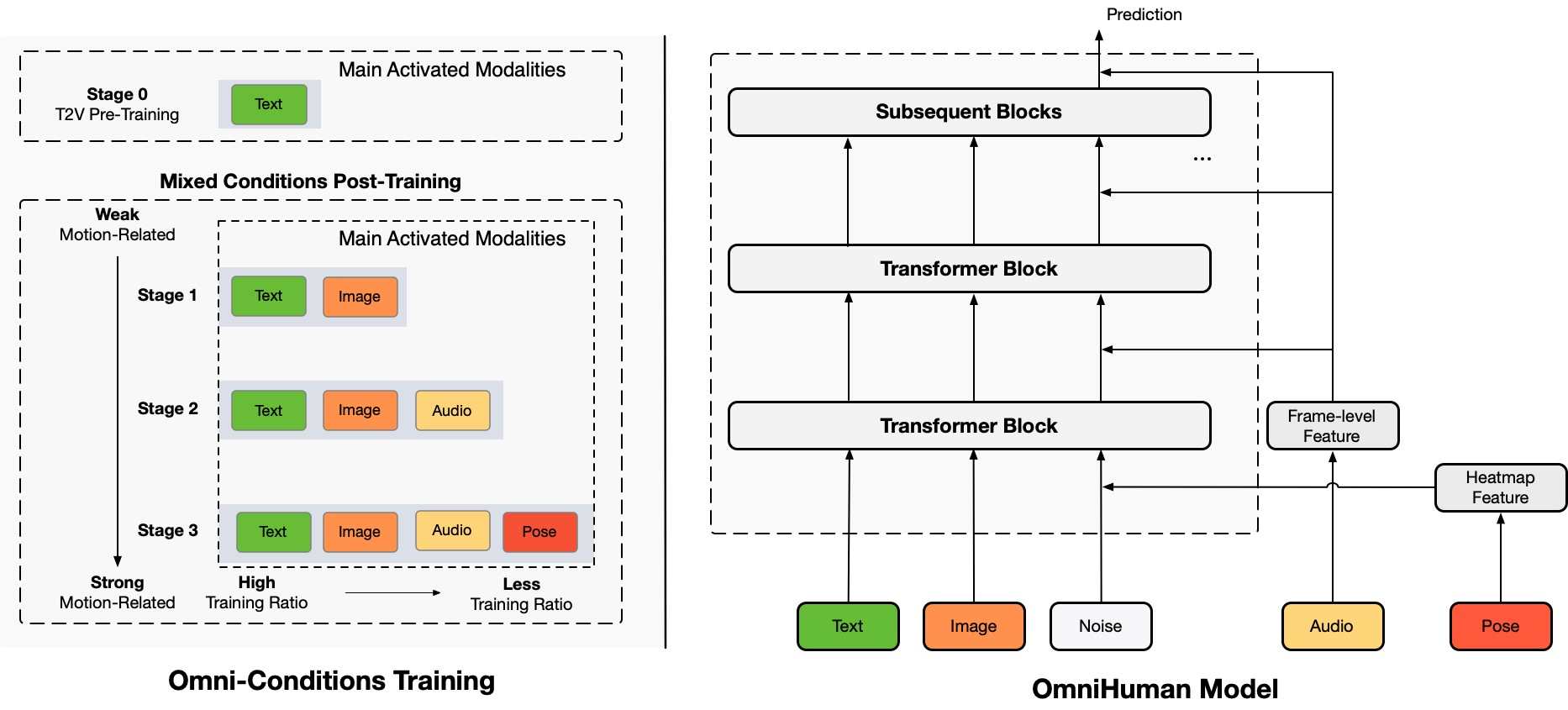
Omnifman’s video generation stage
Mechanism of OMNIHUMAN-1
OMNIHUMAN-1 is built based on 19,000 hours of video training data, analyzing photos, analyzing processing queues, and animating subjects with natural expressions, voice synchronization, and physical movements. AI splits it into two steps.
Motion processing -Compress movement data from sources such as audio or text prompts. Improvement -Comparing the output with the actual video video, the animation is fine -tuned by ensuring accuracy.
One of the outstanding functions is a function to adjust the aspect ratio and the ratio of the body. In other words, while maintaining realistic movements, you can generate videos that fit various formats. It works for non -human characters, such as manga characters and complex poses.

Click to watch the video
Demonstration that blurs the border between AI and reality
Bytedance does not publicly disclose Omnihuman-1, but the initial demonstration is online. One clip shows a 23 -second video of Albert Einstein speech.
The company behind Tactoku has just announced the innovative video model Omnihuman-1.
With just one image and an audio track, you can generate hyperrilic human videos and seamlessly adapt to any aspect or body shape.
Example: pic.twitter.com/smicuc2u6a
-Brian Rome Mele (@brianroeMMELE) February 5, 2025
At the same time, this technology causes serious concerns. As the United States passes the laws for the spoofing spoofing of AI, it is becoming increasingly urgent to distinguish actual content from synthetic media. Such an AI tools can redefine content creation, but open a door to ethical and regulated discussions that have no clear solution.
What is next?
OMNIHUMAN-1 has set a new benchmark of the video generated in AI. The function of creating realistic animations from a single image is no longer a futuristic concept. This is here. The bigger problem is whether the world is ready.