
Just a few months after sending shockwaves through the tech industry, Chinese AI startup Deepseek has returned with another surprise. This time there was no sound.
Without official announcements or media push, DeepSeek quietly uploaded an upgraded version to Facing Face, a public AI repository. This is the latest move from the company that made headlines earlier this year after the original R1 model surpassed heavyweights like the Meta and Openai.
Deepseek Strikes Rate: Chinese AI startup quietly releases new R1 models with vibe coding support
In January, Deepseek surpassed ChatGpt, becoming the most rated free app on Apple’s App Store in the US, with its January 10th launch causing a stir through the tech industry. Deepseek’s open source model not only surpasses its weight, but also did so at small budgets and record times. result? Panic across the market, insightful questions about AI spending in the US, and a temporary blow to investors’ confidence in key AI players, including NVIDIA. The market has been bounced for the majority, but Deepseek’s rise served as a wake-up call.
Now the upgraded R1 model is here. And once again, it’s flying under the radar.
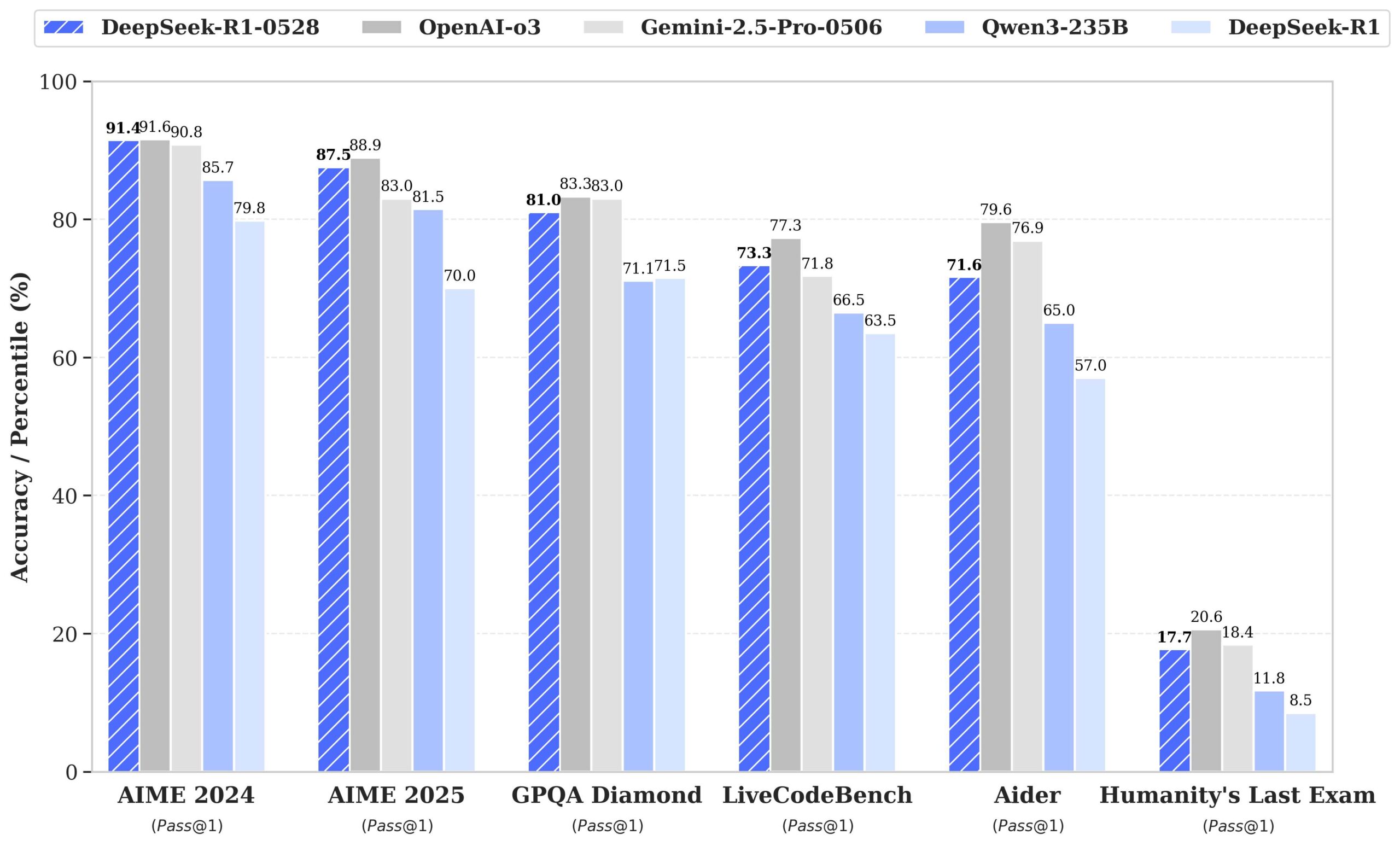
According to DeepSeek, the upgraded model has achieved strong results across mathematics, coding, and inference benchmarks, placing it within prominent distances of top performers such as Openai’s O3 and Gemini 2.5 Pro.
“The DeepSeek R1 model has undergone minor version upgrades, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved the depth of inference and inference with increased computational resources and the introduction of an algorithmic optimization mechanism during post-training.

The newer version of Deepseek R1 is ranked just behind Openai’s O4-Mini and O3 from LiveCodebench. This is a benchmark site that evaluates the inference capabilities of large language models. These types of models are designed to handle more complex tasks through logical, step-by-step thinking.
In a post on Huggingface, Deepseek wrote:
Compared to previous versions, the upgraded model shows significant improvements in handling complex inference tasks. For example, in AIME 2025 tests, the accuracy of the model has increased from 70% in the previous version to 87.5% in the current version. This advancement is attributed to enhanced depth of thinking during the inference process. In the AIME test set, previous models used an average of 12k tokens per question, while in the newer version it averages 23k tokens per question. Beyond improved inference capabilities, this version also offers a lower hallucination rate, greater support for function calls, and a better experience of vibe coding. ”
Deepseek has quickly become a symbol of China’s presence in AI. And it is doing so under increasingly strict restrictions. The US has set restrictions on access to China’s high-end chips and hopes to curb that progress. But so far, the bet has not been paid off.
Just this month, Tech Giants Baidu and Tencent shared an update on how to make the model more efficient as a way to get around the hardware limitations caused by US export controls.
Nvidia CEO Jensen Huang declined to comment on the issue recently.
“The US is based on the assumption that China cannot make AI chips,” Huang said. “That assumption has always been questionable and is clearly wrong now,” CNBC reported.
“The question is not whether China has AI or not,” he added. “It’s already.”
The quiet development of Deepseek’s new model may seem subtle, but the message is loud and clear. China is not waiting for permission. It’s a building.
🚀Want to share the story?
Submit your stories to TechStartUps.com in front of thousands of founders, investors, PE companies, tech executives, decision makers and tech leaders.
Please attract attention
Source link