
Google has just dropped its new AI model into the mix, and with the Gemini 2.5 Flash, it’s already turning its head. This preview release is aimed at developers and businesses looking for something smart, fast and budget-friendly. Google calls it the “main model” and tracks it. It is built for real-time use cases such as chatbots, data extraction, and summaries run at scale.
Flash isn’t here to attract with wild tricks. Here you can do your work efficiently. Google Deepmind has announced that it has announced its release for X.
“Gemini 2.5 Flash just dropped. As a Hybrid inference model, you can control how much “think” it is based on your and.
New features in Gemini 2.5 Flash
Gemini 2.5 Flash is based on the 2.0 version with several major upgrades that target speed and efficiency of the target without cutting corners.
Hybrid reasoning mode
This is Google’s first model to support full hybrid inference. Developers can even arrange the caps according to how much “thinking” the model is, and even organizing the caps, depending on the latency and cost they want to tolerate. Even if inference is dialed down, performance remains ahead of previous versions. It is flexible and not easily broken.
Process more than just text
Flash works with text, audio, images and video. This opens the door to building everything from interactive simulations to apps that turn prompts into code. You can also boost animations and generate functional web tools with a single sentence.
1 Million Token Context Window
Flash can incorporate the mutual content of around six Full Harry Potter books at once. Google is aiming to double that soon. This makes it perfect for using long documents, whole codebases, or huge datasets.
Built for scaling
This is priced to run constantly without breaking the bank. Flash is built for use cases such as large amounts of customer support and enterprise-scale analytics documentation. It’s not just about affordable prices. That’s cost-effective in volume. Its sibling model, Gemini 2.0 Flash-Lite, is priced at $0.075 per million and $0.30 per million, making it competitive by any standard.
Dynamic Resource Management
Another smart feature: Developers can control the amount of computing power used based on the complexity of each request. This means that simple queries do not receive the same heavy treatment as advanced queries. Think of it as a manual transmission for AI reasoning.
Performance Snapshots
Credit O4-Mini to Rolling O4-Mini on Gemini 2.5 Flash release. It’s a day after starting it. Meanwhile, some companies still benchmark their own models. Gemini looks strong. The Gemini 2.5 Flash doesn’t lead every benchmark, but it’s competitive when it matters.
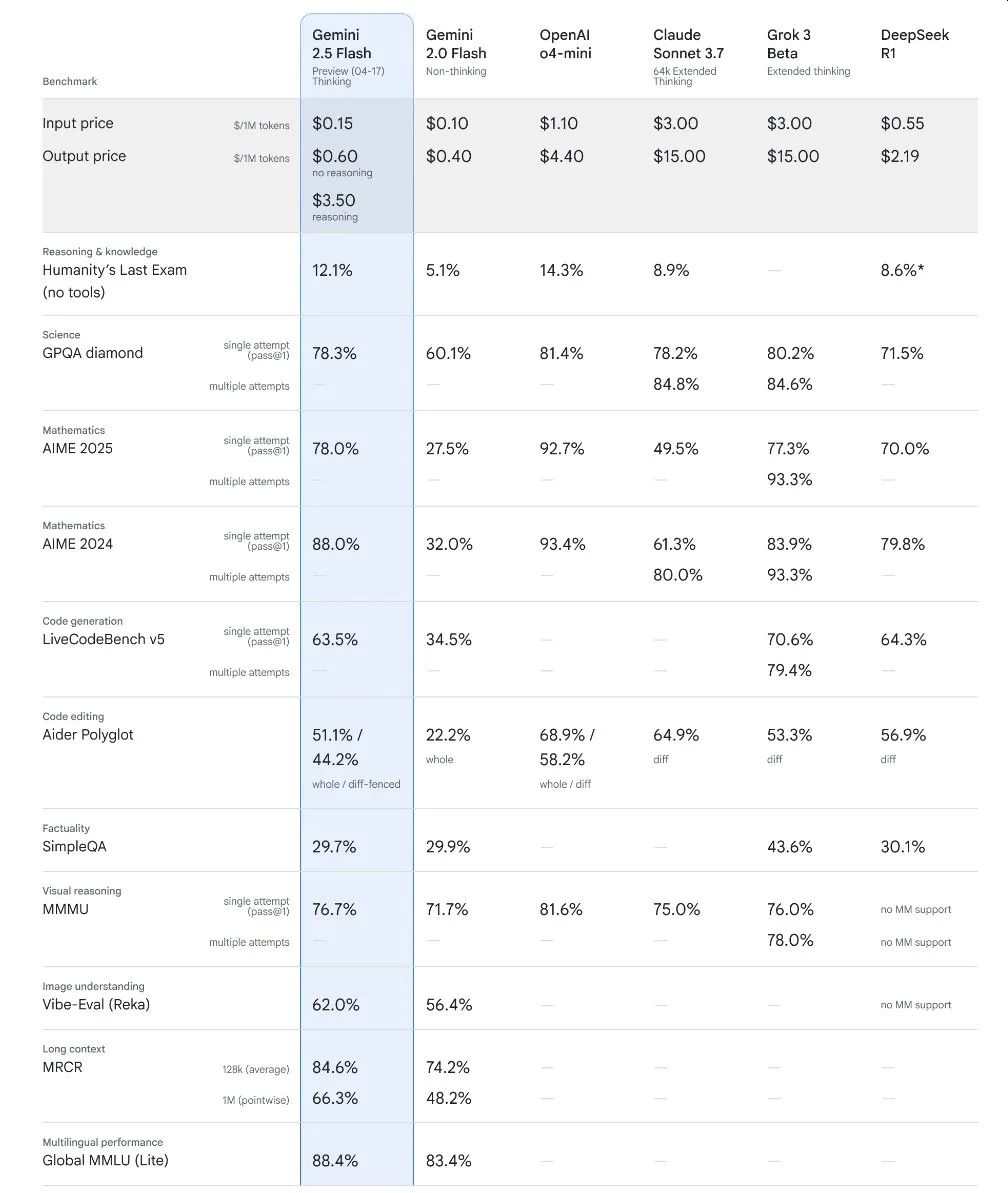
coding:
The coding benchmark SWE-Bench Verified won 63.8% behind Sonnet’s 70.3% Claude 3.7. However, when used in practice, it produces a useful performance that is sufficient, such as generating endless runner games from a working web app or a single line prompt.
Mathematics and Science:
Its brother, Gemini 2.5 Pro, earned 86.7% on the AIME 2025 Math Benchmark and 84.0% on GPQA Diamond. Flash may share similar capabilities, particularly for academic and logical tasks.
Multimodal Task:
It is also excellent in understanding multimodal. The Gemini 2.5 Pro hits 81.7% on the MMMU benchmark, and Flash benefits from the same DNA. It can handle mixed inputs and is ideal for building simulations and analyzing visual data.
That million token window gives you an edge over your rivals. Openai’s O3-Mini is the top with 200,000 tokens. The Deepseek R1 manages 128,000. Only Xai’s Grok 3 matches will flash with input length, but Gemini wins price and flexibility.
A post from X, Lmarena, an open platform for crowdsourced AI benchmarks, praised the Gemini 2.5 Flash’s debut on the leaderboard.
“The latest Gemini 2.5 Flash has arrived on the leaderboard! It will be co-ranked in #2, matching top models such as the GPT-4.5 preview and GROK-3,” the post read.
Lmarena emphasized that Gemini 2.5 Flash is tied to top spots in hard prompts, coding and long query categories, placed in the top four across all benchmarks, 5-10 times cheaper than the Gemini 2.5 Pro.
Deader’s latest Gemini 2.5 Flash has arrived on the leaderboard! Co-ranked in #2, matching top models such as GPT 4.5 Preview & Grok-3! Highlights:
I tied #1 with hard hard prompt, coding, and longer queries
All, top 4 across all categories
5-10x cheaper than Gemini-2.5-pro…pic.twitter.com/qdy2t4cc43– lmarena.ai (formerly lmsys.org) (@lmarena_ai) April 17, 2025
Where to get it
Gemini 2.5 Flash is available in preview:
Google AI Studio: Free trial with a limit of 50 messages per day.
Vertex AI: For production grade work on Google Cloud.
Gemini App: Gemini Advanced users can use it for $20 a month.
ONPREM deployment: Launch of Q3 2025, Gemini models (including Flash) can be deployed via Google distributed cloud for industries that require tight control of data (finance, healthcare, etc.).
You can try the initial version on GoogleI’m in the studio: ai.dev
Google’s Gradual Release Strategy – Release Experimental Versions Early – Lets developers provide feedback and speed up improvements. As AI researcher Sam Witteveen states, “One of the key differences in Google’s strategy is to release experimental versions of the model before going to GA, allowing for quick iterations.”
Early Buzz
Gemini 2.5 Flash is already causing a strong response to X. Posted by 1 user.
“The Gemini 2.5 Flash Preview is a great model. Google is literally winning… Intelligence is getting too cheap, and this is what it means.”
Another post from Deepmind points out its flexibility and calls it a solid fit for chat apps, data extraction and more.
Such caution is exactly what Google is betting. Flash is not trying to replace the biggest and most powerful models. High-frequency, highly efficient lanes open up space.
Competitive heat
Flash enters a busy market. Openai has an O3-Mini. Humanity has a Claude 3.7 sonnet. Deepseek has an R1. Xai has a Grok 3. However, the Gemini 2.5 Flash stands out for its affordable price, flexibility and raw input power blend.
Being able to turn the “Inference” switch on or off gives you controls that developers normally cannot get. You can fine-tune where you want to use and store your computing power.
Google’s broader strategies can also help. The Flash is paired with the more advanced Gemini 2.5 Pro. Flash is built for speed and scale. Pro handles complex tasks such as deep search and autonomous agents. Together, they cover a wide range of needs.
The road ahead
Gemini 2.5 Flash is a powerful signal from Google. AI is smart and accessible. With plans to integrate Flash into a powerful Ironwood TPU and expand the deployment of On-Prem, Google is clearly thinking beyond enthusiasts to the serious corporate realm.
Still, the transparency questions remain. Google has not yet published Flash safety or technical reports. I’ve done this with previous models. It draws some raised brows. However, once Google listens to the test and sticks to its approach to improvement, it can change quickly.
For now, Gemini 2.5 Flash is out in Wild. It’s reasonably priced. It’s fast. And it’s surprisingly clever. Developers can get it through AI studios today or try it out while they’re creating through Vertex AI.
This may be Google’s boldest statement, but useful AI doesn’t have to sacrifice a lot of money.
🚀Want to share the story?
Submit your stories to TechStartUps.com in front of thousands of founders, investors, PE companies, tech executives, decision makers and tech leaders.
Please attract attention