")
Earlier this week, we published an article titled “From SEO to Generation Engine Optimization (GEO), in which we explored how SEO slowly loses grip on digital visibility and enters a new era defined by AI-Native discoveries. This article unravels deeper changes in the way we search, discover, and engage content online.
For over 20 years, Google has decided on the rules. Enter keywords, scroll through the blue links and click a few. The model built an empire that weighed over $20 billion. But today, the system feels more and more outdated.
Users have not searched since 2024. Whether it’s ChatGpt, Gemini, or bewildered, people expect instant, high-quality answers that arrive in a single conversational box. They don’t want 10 blog posts. They want the best answer – now.
“In the era of ChatGpt, Prperxity and Claude, generation engine optimization is positioned to be a new playbook of brand visibility. It’s not just an algorithmic game, but it’s cited by it.
Brands that win at GEO do not appear exclusively in AI Responses. They shape them. ” – A16Z.
This article looks like this: If your AI tools answer more questions than search engines, how do you do it in real time?
Intro: Shift restructuring web search behavior
This structural shift has even led to the declaration of an untimely death in SEO. Others consider it to be completely irrelevant. Now there is more and more searches being made within LLM interfaces like ChatGPT. However, what is actually happening beneath the surface is an evolution of the search itself, and ultimately benefits the user. AI tools increasingly prioritize quality, relevance, trust, and authority over keyword-packed blog posts and operational optimization tactics.
There is a quiet revolution in the way people search for information online. Instead of turning to traditional search engines like Google, millions are asking ChatGpt, Claude, Prperxity, and other AI tools to give answers directly. Cosmetics aren’t the only changes in user behavior. Change who controls visibility, what content is surfaced, and how creators and publishers benefit (or not).
But there is one important question that a few people are asking. Where did this real-time data actually come from?
If your AI tools provide the latest, timely, concrete-looking answers, if they are trained with static data, how are you pulling it out?
So how does LLMS like ChatGpt, Gemini, Prplexity pull out real-time answers in the world of static training? Let’s break down the three main sources they rely on, how the pipeline works behind the scenes, and what creators and publishers have to do to make it visible in the AI-driven search world.
Credit: ML6
1. Search Engine: The first line of real-time search
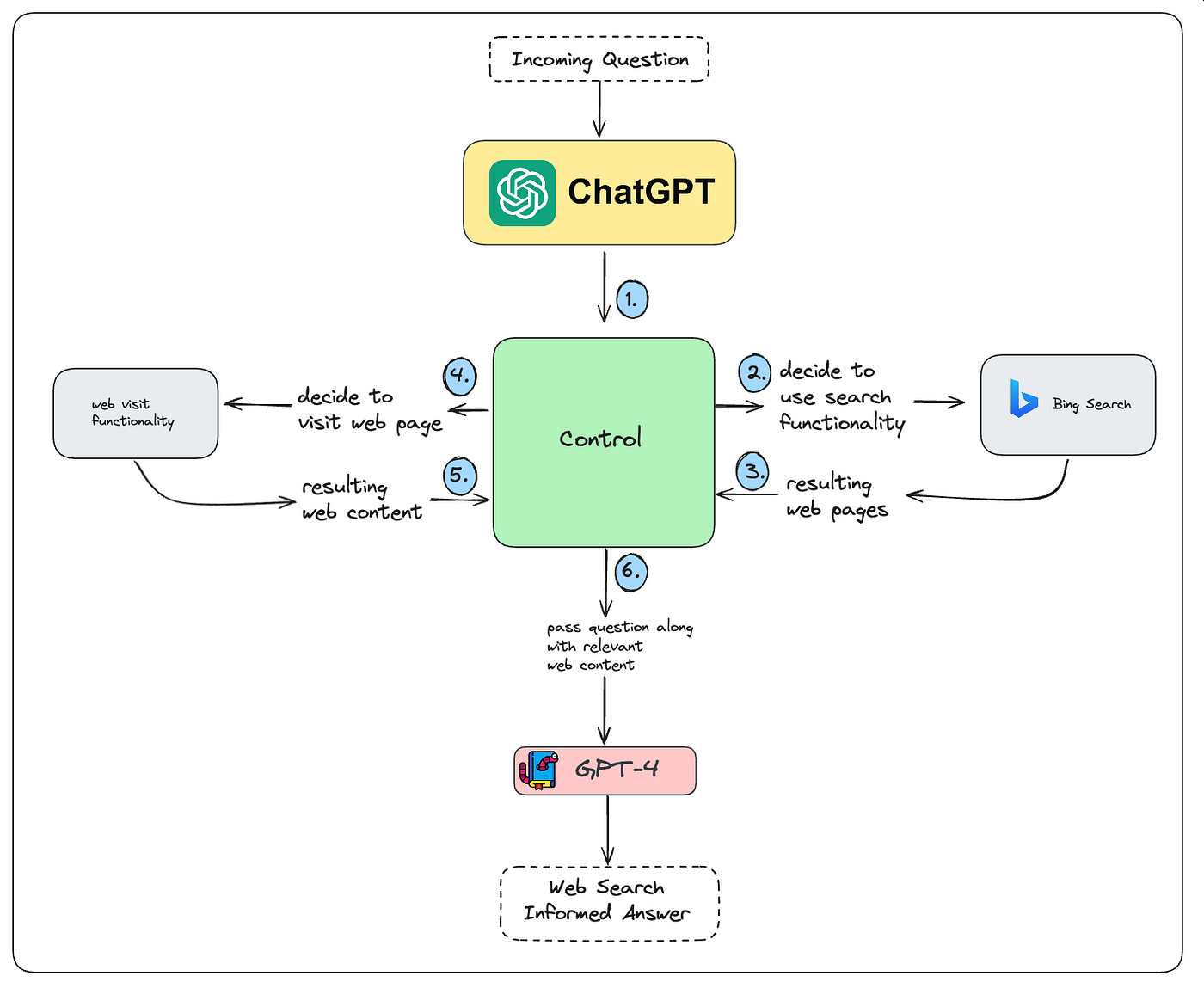
When LLM provides real-time responses like ChatGPT, they often use search engines as the backend. For example, ChatGpt with browsing uses the Bing Search API to query the web just like it does. It then reads the top few results, extracts relevant content, and summarizes the natural language answers.
This means that the traditional ranking layer (Bing’s algorithm) determines which websites LLM will first appear. If the content is not ranked well, it is unlikely that AI will surface or quote.
Credit: ML6
2. Specialized API: Real-time structural data
For example, if you ask ChatGpt, “How’s the weather in Tokyo now?”, you won’t get hallucinated. Get live data from OpenWeatherMap or similar APIs.
If LLM needs accurate, structured, rapidly changing data (such as stock prices, weather, sports scores), they rely on specialized APIs. These include:
FinanceAPIS like Alpha Vantage and Yahoo Finance Weather APIs newsapi.org OpenWeathermap News APIs like crypto and Sports APIs
LLM does not infer or generate this data. It queries live, parses the results, and inserts them into the response.
3. Search Total Generation (RAG): Private or Dynamic Knowledge Plugin
Imagine a company using a GPT-based assistant to answer questions from an internal HR policy. Instead of relying on the public internet, the model queries a private database or indexed document system to retrieve the latest internal policy documents.
Beyond public data, many LLMs use RAG systems to query private or updatable knowledge bases. This is common in enterprise AI, customer support tools, or internal AI agents. The model first retrieves the relevant context (from a PDF, database, or document index) and generates an answer based on both its training and newly retrieved data.
Putting it all together: How a pipeline works
Here is the simplified flow:
Users ask for time-sensitive questions LLM generates search/API queries and sends them to real-time sources such as Bing search API or specialized external API real-time sources (Bing, API, or internal documents).
This is why it’s important for publishers and content creators.
The bottom line is: If you want to display content in AI-generated answers, you must display it in the sources used by AI. In other words,
The content ranked in Bing (and possibly Google) publishing content is a simple and easy content for machines to parse structured data in a way that is available to APIs or RAG systems.
In short, if you can’t retrieve the content, it’s hard to forget.
What’s coming next: AI crawlers and direct indexes
Openai has already launched GPTBOT. GPTBOT is visiting websites where Crawler visits websites to build their own indexes. This suggests a future where LLMS may no longer depend on Bing or Google, and may depend on its own web snapshots. So it’s important to control how content is structured, delivered and accessible to AI systems.
Conclusion: Make it look not just people, but AI
In the web AI layer, you won’t win simply by exposing it. You win by being rotatable, releasable, and quotable. The future of visibility is not about keywords, but that LLMS is the source you want to quote.
Now that I know where LLM retrieves real-time data, my only question is: Will they find yours?
🚀Want to share the story?
Submit your stories to TechStartUps.com in front of thousands of founders, investors, PE companies, tech executives, decision makers and tech leaders.
Please attract attention
Source link