
Openai has dropped a fresh batch of audio models, shaking how voice AI works. The new lineup of audio models is designed to push audio AI forward. The new release includes text-to-speech and speech-to-text models that move things forward with speech recognition and production.
This release includes GPT-4O-MINI-TTS, a text-to-speech model that accurately controls tone and timing, and two advanced speech-to-text models, GPT-4O transcription and GPT-4O-MINI trans access.
These models are now available through Openai’s API and Agents SDK, making it easier for developers to build sophisticated, voice-powered applications. Openai also launched Openai FM, a platform for testing speech models from texts, and introduced a contest to encourage creative use of technology. The announcement creates great interest from the developers and the tech community, highlighting the potential to rebuild voice-driven software.
Speech and transcription upgraded from text
The latest models include GPT-4O-MINI-TTS for text-to-speech, built to handle subtle speeches with better control over tone and timing. Developers tweak how the words are spoken, opening up the possibilities for a more expressive, AI-driven voice.
For speech and text, Openai introduced GPT-4O transcription and GPT-4O-MINI-Transcribe. Both models outperform previous versions such as whispers by improving transfer accuracy across noisy settings and various accents. It handles real-world conversations more effectively and helps you with customer service, content creation and accessibility tools.
Bring AI speech to more developers
Openai involves these models in its APIs, allowing developers to connect to their applications. Pricing is competitive:
GPT-4O Transcription: $6 Audio Input Token per Million ($0.006 per Minute)
These updates streamline the process of integrating high-quality audio processing into your app, such as live customer support, automatic note-taking, or interactive voice assistants.
Openai FM and Community Engagement
To show what these models can do, Openai launched Openai.FM, a platform that allows users to test the functionality of text-to-speech. In addition to this, they have launched a contest to encourage creative applications of the latest technology. From personalized assistants to generating audio content, expect to see developers experimenting with new ways to use AI voices.
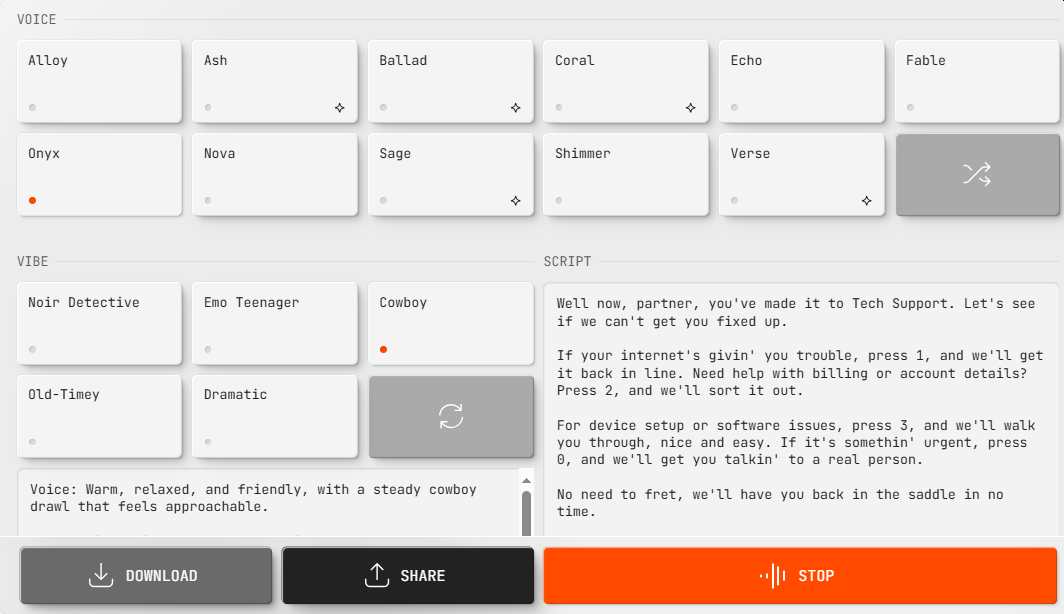
An interactive demo for developers to try out speech models from new text in the OpenAI API. (Credit: Openai)
According to Openai, three new cutting edge audio models of the API include “two voice-to-text models – out-performed whispers, new TTS models – allowing you to *tell how you * speak it, and the Agents SDK supports audio and allows you to easily build voice agents.”
Three new cutting edge audio models for the API:
🗣Chasing two speech to text model – perform a whisper
💬New TTS Model – You can tell it *How*🤖Agent SDK now supports audio, making it easy to build voice agents.
Try TTS now at https://t.co/mbtolnyyca.
– Openai Developer (@openaidevs) March 20, 2025
Early reactions and industry impact
The launch has been well received, especially among developers looking for better transcription and speech synthesis options. Some early adopters, like Eliseai, have already integrated speech models from Openai’s text into their property management platform, reporting more natural and expressive speech interactions.
Openai has not stopped here. The company is working to expand its voice technology with more voice options, ultimately bringing AI-driven conversations closer to human-like exchanges. The huge movement of audio generated by AI has intensified the competition for voice technology.
Source link