The rise of China’s AI startup DeepSeek is nothing surprising. After exceeding ChatGpt in the App Store, Deepseek sent a shock wave to the world of TheM and caused frenzy in the market. But not all attention was positive. DeepSeek’s website faces an attack that has forced the company to suspend registration, and some suspicions depend on the H800 chip, which is claimed to be used by the startup, but depends on the export -restricted NVIDIA H100 chips. I wondered if I was doing it.
Currently, a breakthrough from a researcher at the University of California Berkeley is challenging some of these assumptions. The Doctor’s team candidate, Jiayi Pan, has been able to copy the DeepSeek R1-Zero core function for less than $ 30. Their research could cause a new era of a small model RL revolution.
Their survey suggests that sophisticated AI inference does not need to have a large -scale price tag that can potentially shift the balance between AI research and accessibility.
Berkeley researchers reproduce Deepseek R1 for only $ 30. This is a challenge to the H100 story
The Berk Lae team says that he worked on Deepseek’s 3 billion parameter language models and trained through enhanced learning to develop self -verification and search skills. The goal was to solve arithmetic -based issues by reaching the target number. This was completed for only $ 30. Compared to that, O1 API of OPENAI costs $ 15 per million input tokens. This is more than 27 times the price of Deepseek-R1, only $ 1 million per million. Bread considers this project as a step to lower the barriers to strengthen learning scaling research, especially in the minimum cost.
But not everyone is on board. Nathan Lambert, a machine learning expert, has doubted DeepSeek’s claim that training for 67.1 billion parameter models cost only $ 5 million. He argues that this number is probably probably excluding major costs such as research staff, infrastructure, and electricity. In his estimation, DeepSeek AI’s annual cost of $ 500 million to $ 1 billion. Still, the results are outstanding. In particular, considering that the top AI companies in the United States have poured $ 10 billion in AI initiatives.
Experiment decomposition: Small model, big impact
According to JIAYI PAN’s Nitter, the team has successfully reproduced DeepSeek R1-Zero using a small language model with 3 billion parameters. When enhanced learning in the countdown game, the model has developed a self -verification and search strategy, that is, the advanced AI system key ability.
Important take -out from their work:
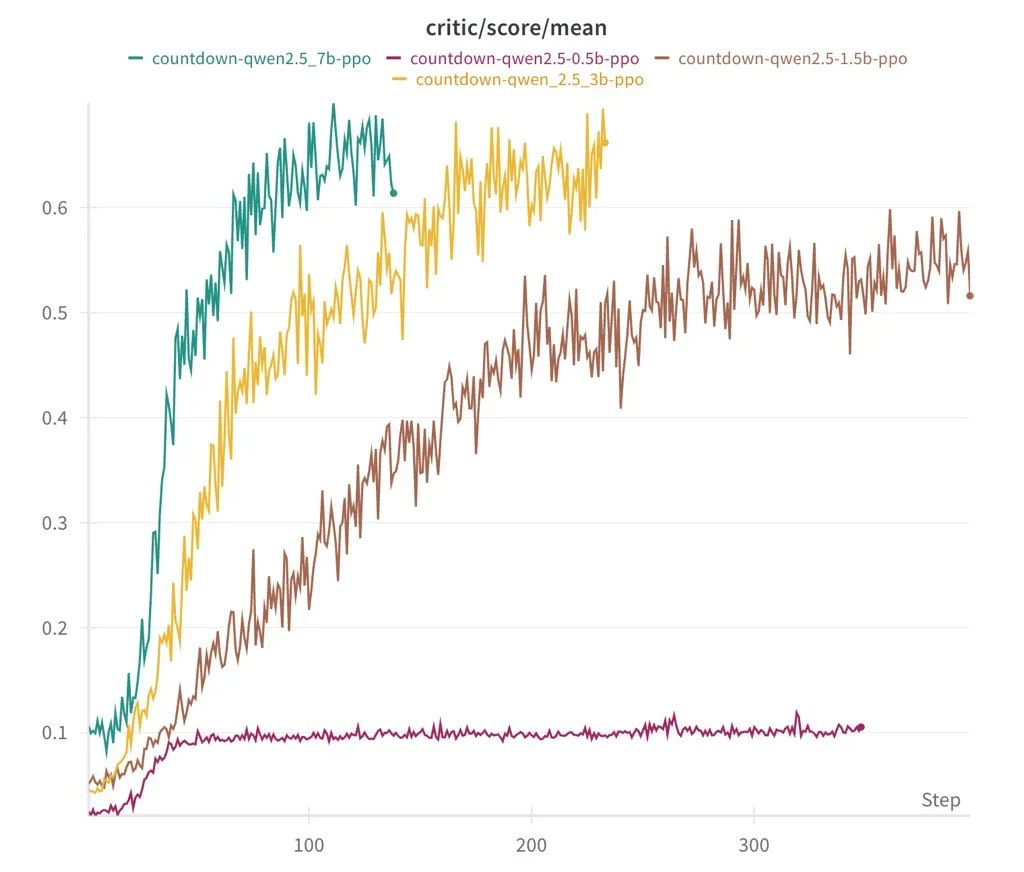
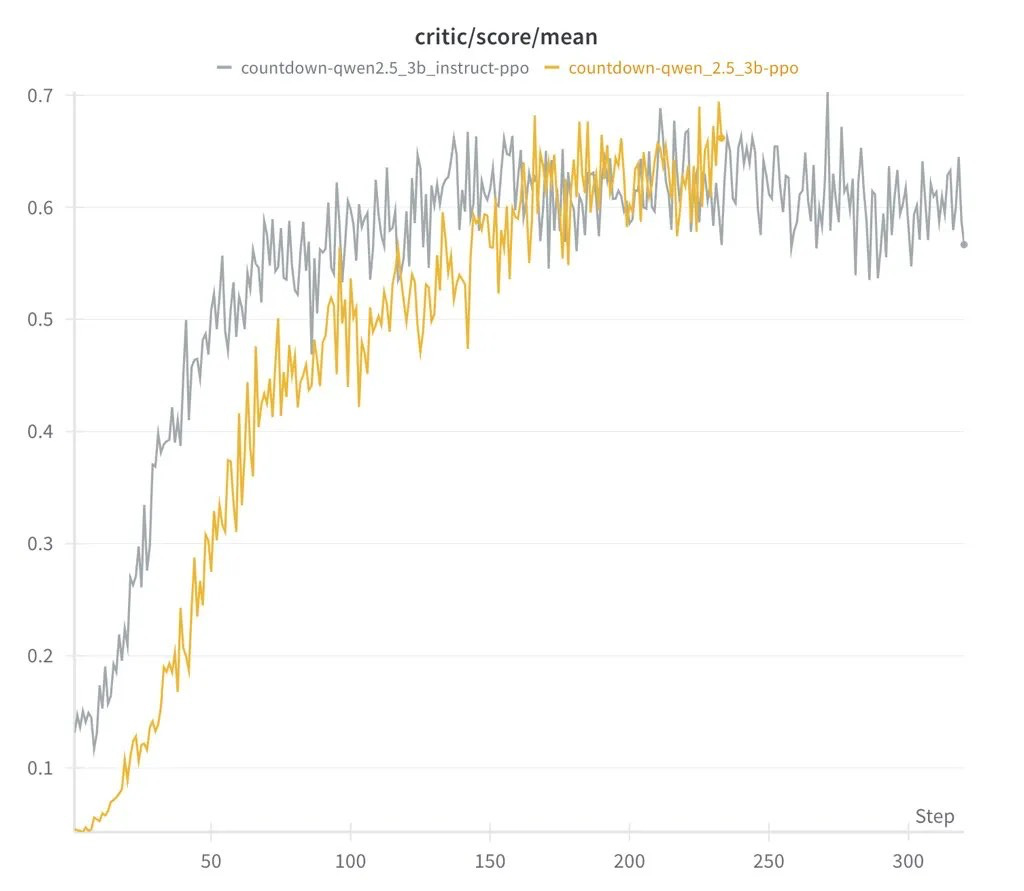
They have successfully reproduced the DeepSeek R1-Zero method of less than $ 30. Their 1.5 billion parameter models showed advanced inference skills. The performance was equivalent to a larger AI system.
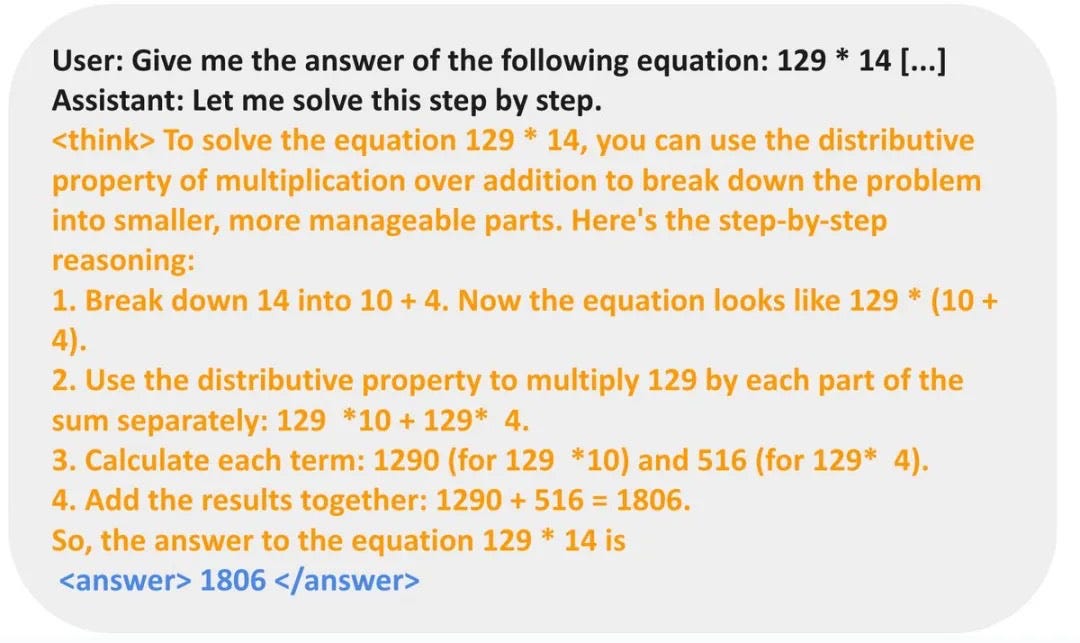
“Deepseek R1-Zero is reproduced in the countdown game, but it works. Through RL, 3B base LM develops all self-verification and search capabilities on its own. Bread said in X.
Deepseek R1-ZERO is reproduced in the COUNTDOWN game, but it works.
Through the RL, the 3B base LM develops self -verification and search skills on its own.
You can experience the moment of Ahah yourself with <$ 30
Code: https: //t.co/b2isn1prxv
This is what we learned pic.twitter.com/43bvymms8x
-Jiayi Pan (@JIAYI_PIRATE) January 24, 2025
Breakthrough of reinforced learning
Researchers started with basic language models, structured prompts, and fundamental rewards. Later, we introduced Renecation Learning through Countdown, a logic -based game that was adapted from a British television program. In this task, the player must use arithmetic operations to reach the target number. This is a setup that encourages the AI model to improve inference skills.
Initially, AI generated a random answer. Through trial and error, we examined our own response and started adjusting the approach with each repetition. This makes a mistake in how humans solve problems. Even the minimum 0.5 billion parameter models could only estimate simple, but with more than 1.5 billion, AI began to show more advanced inference.
“Deepseek R1-Zero is reproduced in the countdown game, but it works. Through RL, 3B base LM develops all self-verification and search skills.
https://github.com/jiayi-pan/tinyzero
This is what we learned, “said Bread in Nitter post

Surprising discovery
One of the most interesting surveys was that different tasks began to develop a clear problem -solving technology for the model. Countdown learned to improve search and verification strategies, repeat answers, and improve. When working on multiplication issues, it applied a distribution method. When mentally solving complex calculations, break the numbers as humans do.
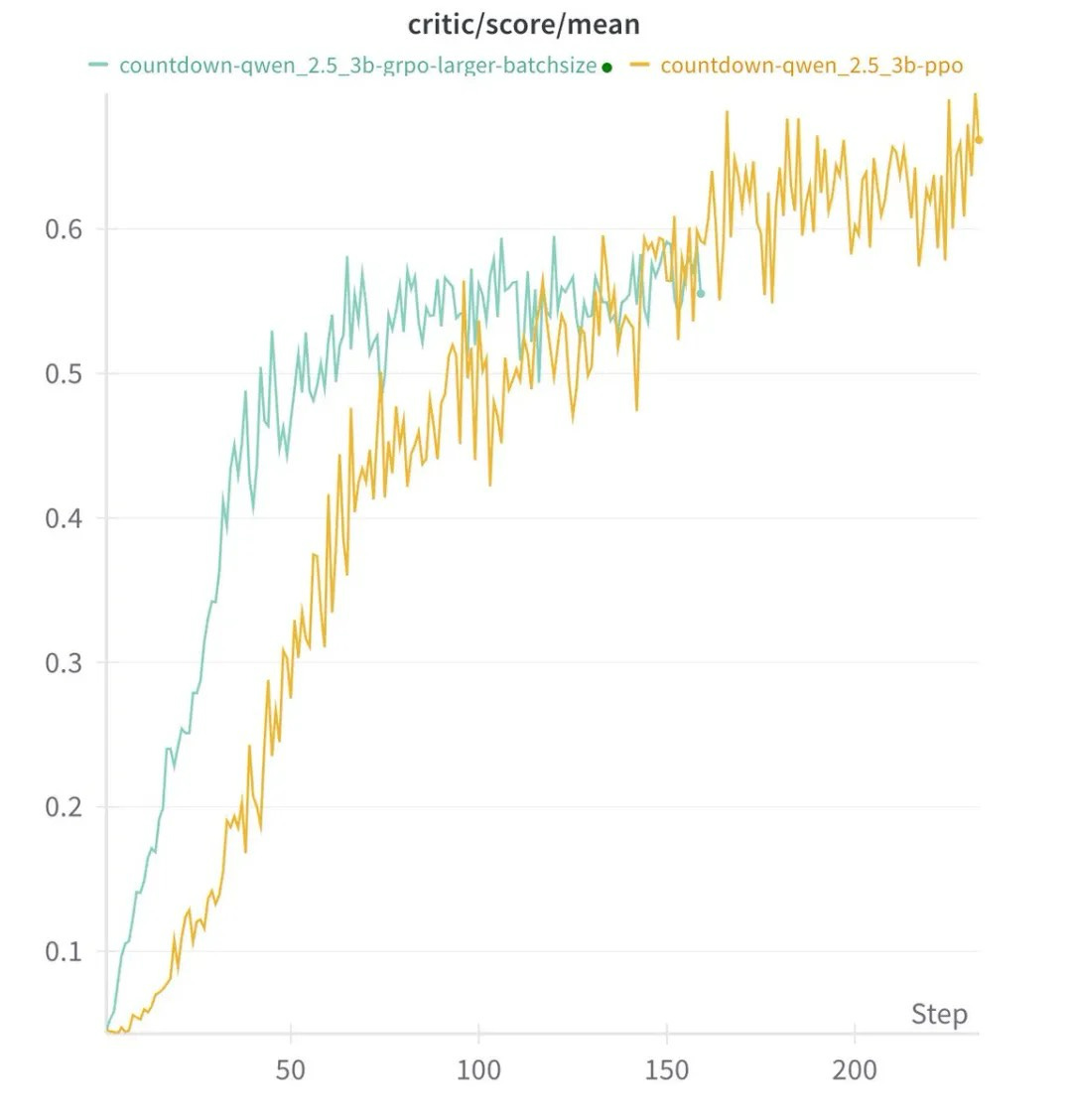
Another notable discovery is that the choice of enhanced learning algorithms, whether PPO, GRPO, or Prime, has little effect on overall performance. The results are consistent in various ways, suggesting that it plays a major role in the formation of AI functions than a specific algorithm used with structured learning and model size. This challenges the concept that sophisticated AI requires a huge amount of computing resources, indicating that complex inference may appear from efficient training technology and well -built models.
The important point from this study was how the model compatible with the problem -solving technology based on the task at hand.
Wiser AI through task -specific learning
One of the most interesting take -out is how AI adapted to various issues. In the countdown game, the model learned search and self -verification skills. When testing on a multiplication problem, we used it to disassemble the distribution method before solving the distribution method.
Instead of blindly guessing, AI has improved the approach to multiple repetitions and verifies and revised its own answers until the correct solution is landed. This suggests that models can evolve special skills according to tasks.
AI accessibility shift
The cost of a complete project is less than $ 30, and the code is published on GitHub, so this survey makes it easier for more developers and researchers to access advanced AI. We challenge the concept of a budget of $ 1 billion for groundbreaking progress, and strengthen the idea that smart engineering can often exceed Blue Force spending.
This work reflects a vision that Richard Sutton, the main character of reinforcement learning, has long defended, and has argued that simple learning frameworks could have powerful results. The Berklaw team’s survey suggests that he is right. The complex AI function does not necessarily require a large scale computing, but an appropriate training environment.